Good morning everyone.
With Everything, when I search for a word in the content of a directory (function ‘content:<testo>’ ), I will receive in response the list of all the files that contain the word (or the argument in quotes).
This is because, if I understood correctly, Everything creates (or uses) a DataBase made up of all the words of the files in the directory with some (or a lot of) collateral information useful for identification.
Is it possible to access that db and know how it is structured? Is it possible to use it with Access? Is it possible to manipulate it for one's own use?
Thanks for your answers.
Bye.
Alberto
File contents analysis
Re: File contents analysis
Reading the Everything.db directly is not supported.Is it possible to access that db and know how it is structured?
Yes, with the Everything SDK.Is it possible to use it with Access?
No, the Everything SDK is read-only.Is it possible to manipulate it for one's own use?
The closest thing Everything supports to manipulating the database is file lists.
db2efu
-
meteorquake
- Posts: 523
- Joined: Thu Dec 15, 2016 9:44 pm
Re: File contents analysis
If I understand one point there correctly, I don't think Everything creates/uses a Database of all the words of the files in the directory, I would think it does a hard non-storing scan of the files with any calculative information discarded after each file's assessment.
As a second matter, content: still seems to me somewhat of a basic tool for basic search tasks, very useful as present if that's all that's needed, whereas something like AgentRansack will (again using a hard scan without storage) show all the hits within each file with their context, so you can usefully do proximity searches of phrases within files (using regular expressions) and see all the hits (such as 'monument' within 200 characters of 'Edinburgh'). Probably everyone has their favourite searcher for such close inspection searches, and I'm not convinced Everything should be trying to match such tasks beyond what it already does, unless it wants to replace the normal full-file preview to show the result hits within a selected file if asked (e.g. using something like showhits:<expression or blank to use first content: value>, which I don't think people would object to as it would be handy - maybe that could be a todo.
As a second matter, content: still seems to me somewhat of a basic tool for basic search tasks, very useful as present if that's all that's needed, whereas something like AgentRansack will (again using a hard scan without storage) show all the hits within each file with their context, so you can usefully do proximity searches of phrases within files (using regular expressions) and see all the hits (such as 'monument' within 200 characters of 'Edinburgh'). Probably everyone has their favourite searcher for such close inspection searches, and I'm not convinced Everything should be trying to match such tasks beyond what it already does, unless it wants to replace the normal full-file preview to show the result hits within a selected file if asked (e.g. using something like showhits:<expression or blank to use first content: value>, which I don't think people would object to as it would be handy - maybe that could be a todo.
Re: File contents analysis
I understand and I move on to the explanation of why I asked the question.
During the last twenty years I have entrusted every thought of mine - or rereading, or criticism, or translation, or story - to the computer's memory. Now, in old age and with a view to transmitting a historical memory, I would like to index all the topics that I have touched on during these years.
The best solution seems to me to be able to search for a significant word and find where this word is cited and then leave the consultation of the complete text that includes it to the person who did the research. In your opinion, how can I achieve this goal?
During the last twenty years I have entrusted every thought of mine - or rereading, or criticism, or translation, or story - to the computer's memory. Now, in old age and with a view to transmitting a historical memory, I would like to index all the topics that I have touched on during these years.
The best solution seems to me to be able to search for a significant word and find where this word is cited and then leave the consultation of the complete text that includes it to the person who did the research. In your opinion, how can I achieve this goal?
-
meteorquake
- Posts: 523
- Joined: Thu Dec 15, 2016 9:44 pm
Re: File contents analysis
I think searching for a word is fine, as long as you use the right file extensions.
In my case I save a lot of things as .txt because they are easy to scan for words
I have pdf and djvu files automatically converted to have a .txt version along with them, so I content scan and find the txt, and can open the associated pdf
* If you save as doc or odt you could have a similar thing, there's probably a program somewhere that will do so
* I think Everything would work fine for that, although AgentRansack and others have the edge in that display hits on each line within a file
* You can also get programs that index the contents of everything (including emails) for instant finding, they tend to create huge storages for this.
* Thesauric etc finds - some programs would be able to do this, so in searching for 'hot', 'boiling' and 'burning' would also be found, and in searching for 'realise', 'realize' would also be found
* You could actually concatenate all your notes together and pass it to an AI engine to summarise, and pass them as individual files to get summaries of each, as they are getting better at this. I think someone would need to script the latter task.
* I've created my own 'memories' for people and I tend to put them all into a single file, dragging items into sections
* You could also put them all into a single file and put codes before each entry and then sort them alphabetically to help that task (eg HSE for house), and then finalise them (removing the codes in the process)
In programs like word or libreoffice you can -
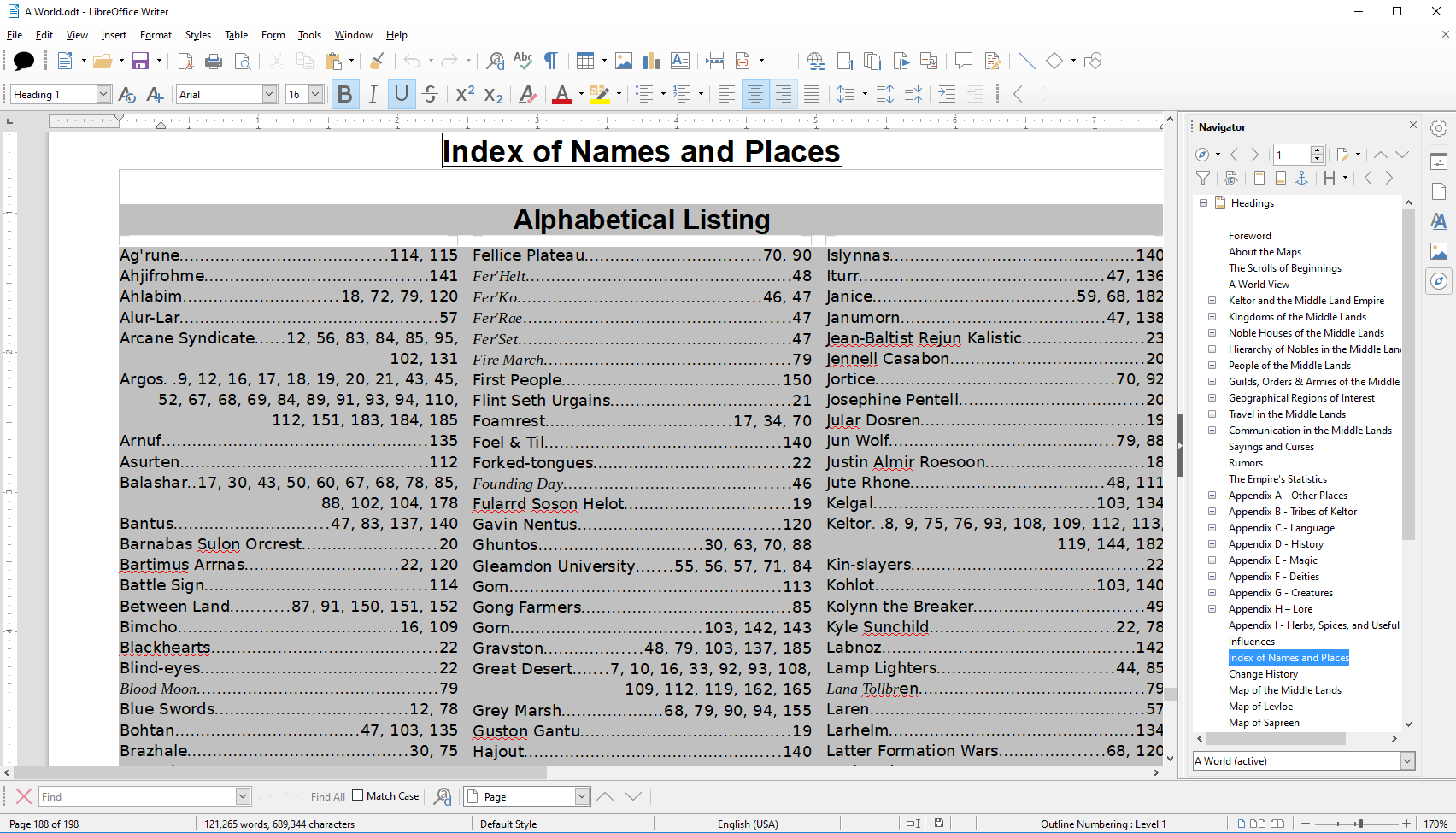
* Use Headings for each section, and the program can build a contents with page numbers
* Put index entries for topics at any point (e.g. childhood, mum could be placed for a sentence), and it will generate an index at the end, so that single sentence would appear in the index at multiple points.
See this example - https://ask.libreoffice.org/uploads/ask ... a52f42.png
In my case I save a lot of things as .txt because they are easy to scan for words
I have pdf and djvu files automatically converted to have a .txt version along with them, so I content scan and find the txt, and can open the associated pdf
* If you save as doc or odt you could have a similar thing, there's probably a program somewhere that will do so
* I think Everything would work fine for that, although AgentRansack and others have the edge in that display hits on each line within a file
* You can also get programs that index the contents of everything (including emails) for instant finding, they tend to create huge storages for this.
* Thesauric etc finds - some programs would be able to do this, so in searching for 'hot', 'boiling' and 'burning' would also be found, and in searching for 'realise', 'realize' would also be found
* You could actually concatenate all your notes together and pass it to an AI engine to summarise, and pass them as individual files to get summaries of each, as they are getting better at this. I think someone would need to script the latter task.
* I've created my own 'memories' for people and I tend to put them all into a single file, dragging items into sections
* You could also put them all into a single file and put codes before each entry and then sort them alphabetically to help that task (eg HSE for house), and then finalise them (removing the codes in the process)
In programs like word or libreoffice you can -
* Use Headings for each section, and the program can build a contents with page numbers
* Put index entries for topics at any point (e.g. childhood, mum could be placed for a sentence), and it will generate an index at the end, so that single sentence would appear in the index at multiple points.
See this example - https://ask.libreoffice.org/uploads/ask ... a52f42.png
{kind=link}
-
ChrisGreaves
- Posts: 697
- Joined: Wed Jan 05, 2022 9:29 pm
Re: File contents analysis
Hi ag.ar. On reading Meteorquake's recent post I see that "Index" is mentioned. Thirty years ago I wrote an MSWord/VBA "Interesting Words" engine which I still use today.
The Interesting Words engine is a rules-based (that is, user-directed) mechanism for extracting Interesting Words from any chunk of text (Selection, Sentence, Paragraph, Document etc.).
When applied to a document, the table of Interesting Words can be used to implement AutoMark and build an Index in lightning time.
I have attached a UserGuide with examples of Rules Tables.
Re-indexing this document took just under half a minute (Elapsed time 00:00:29 on an old DEL laptop Win7)
Remember that you can harvest Interesting words from any document or collection of documents.
Repeatedly.
Indxr is free.
Cheers, Chris
- Attachments
-
- UserGuide.DOC
- (1.61 MiB) Downloaded 53 times
Re: File contents analysis
Hi meteoquake and ChrisGreaves, thank you so much for your suggestions. As a first try I will try to see the suggestions of AI, even if I am philosophically against AI (that's another story), then I will try the script of Chris and then I will study the results a bit. Thanks again for your availability and I will keep you posted. Cheers! 
albertoragazzi.com
albertoragazzi.com